In scenarios such as SEO monitoring, AI training data, and competitive intelligence analysis, reliably acquiring Google SERP data remains a core issue. Enterprises typically choose between three solutions:
The technical costs, stability, and scalability of these different solutions vary significantly. This article systematically analyzes the differences between the three from the perspectives of architecture, operational costs, and scalability, and highlights why more and more enterprises are choosing Search Infra as their long-term data infrastructure solution.
I. Google API: Does the Official Interface Equal Complete SERP Data?
Many enterprises, when searching for "Google API," are actually hoping to obtain complete search results page data (SERP).
However, several points need clarification:
Therefore, the "Google API" is more of a conceptual search requirement than a true solution to replace the SERP data collection system.
For enterprises requiring complete SERP structure data, relying solely on official interfaces often fails to meet business needs.

II. Web Scraping: Seemingly Low-Cost, But Highly Maintainable
Web Scraping was the most common solution in the early days. The technical path typically includes:
It can work in the short term, but when the business scales up, problems quickly become apparent:
1. High IP blocking and CAPTCHA costs
Search engine anti-scraping mechanisms are becoming increasingly strict; large-scale crawling easily triggers blocking.
2. Frequent HTML structure changes
Even minor adjustments to the page structure can lead to parsing failures, requiring continuous maintenance. 3. Uncontrollable Costs
Servers, bandwidth, proxy pools, and engineer maintenance time are all long-term hidden costs.
When query volume reaches tens of thousands or even millions per day, a self-built crawling system often becomes a technical burden rather than an asset.

III. Search Infra API: Born for Scalable SERP Data
Compared to Google API and Web Scraping, the optimal solution between self-built and outsourcing is a professional SERP API infrastructure.
Search Infra provides a high-concurrency, structured, and scalable search data interface. Its core advantages are reflected in the following aspects:
1️⃣ Complete SERP Structured Output
Unified JSON format output reduces parsing costs and facilitates direct entry into data analysis or AI processing workflows.
2️⃣ High Concurrency and Global Node Support
The Search Infra API architecture is designed for high-scale queries, supporting:
Compared to self-built Web Scraping systems, there's no need to maintain proxy networks and browser clusters.
3️⃣ Stability and Continuous Maintenance Handled by the Platform
HTML structure changes, anti-scraping upgrades, and IP policy optimizations are all handled at the platform level.
Enterprises don't need to invest engineering resources in repeated maintenance.
This makes the Search Infra API more like:
"Search Data Infrastructure as a Service"
rather than a simple data scraping tool.
4️⃣ Clearer Cost Structure
The true cost of self-built Web Scraping includes:
The Search Infra API uses an API call billing model, with a clear and predictable cost structure, making it more suitable for long-term enterprise planning.
IV. Google API vs Web Scraping vs Search Infra API Comparison Summary
| Dimensions | Google API | Web Scraping | Search Infra API |
|---|---|---|---|
| Data integrity | Partial coverage | Crawlable but Unstable | Fully Structured SERP |
| Stability | High | Low | High |
| Operational Costs | Low | High | Extremely Low |
| Scalability | Limited | Complex | Designed for High Concurrency |
| Enterprise Suitability | Medium | Early-Stage Projects | Enterprise-Scale |
V. Why are Enterprises Moving from Web Scraping to Search Infra API?
With the explosive growth of AI applications and SEO data demands, data collection has evolved from a "tool problem" to an "infrastructure problem."
What enterprises truly need is:
Instead of constantly fighting anti-scraping systems.
In this context, the Search Infra API has become a more strategic solution, replacing traditional Web Scraping and becoming the mainstream path for enterprises to obtain Google SERP data.

Search Infra
Author
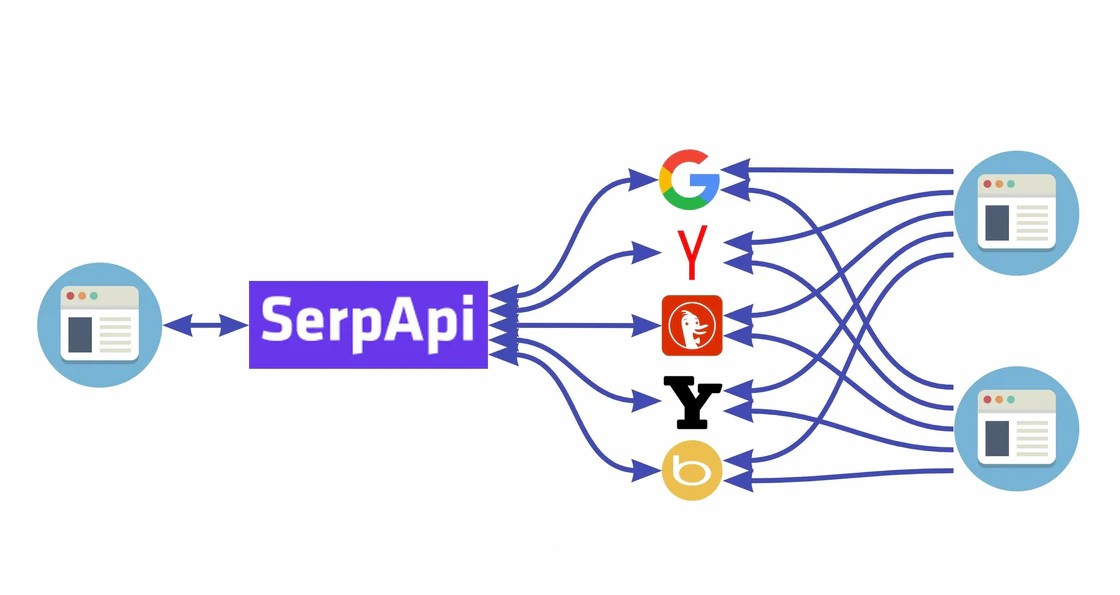
 SERP API
SERP API
Serp API
Google API
SERP API
Serp API
Google API